If you are familiar with how microservices architecture functions, then you must be familiar with the problems this architecture encompasses. The most dreaded one being Transaction Handling.
Ideally, a microservices architecture should be designed in such a way, that the transaction should not span across different services. Although in some situations this is unavoidable. Let’s take an example of a huge microservices based eCommerce architecture. Let’s say one microservice handles placing orders, and another microservice manages inventory. In such a situation, if an order succeeds, then you have to decrease the inventory (or stock) of the items which the user ordered. If the order failed, then the decrease inventory operation should NOT take place. Or, we can say that we want to ensure Atomicity for the whole operation. Either the order placement and decrease inventory — both should be successful, OR both should fail.
There are some design level patterns which can ensure a Distributed Transaction among different microservices. Let’s take them one by one.
Two-Phase Commit (2pc)
As the name suggests, the process is divided into two phases and is handled by an instance called Transaction Coordinator. The main job of this coordinator is to coordinate or synchronize the status of the different microservices in a distributed environment. The process starts with the prepare phase.
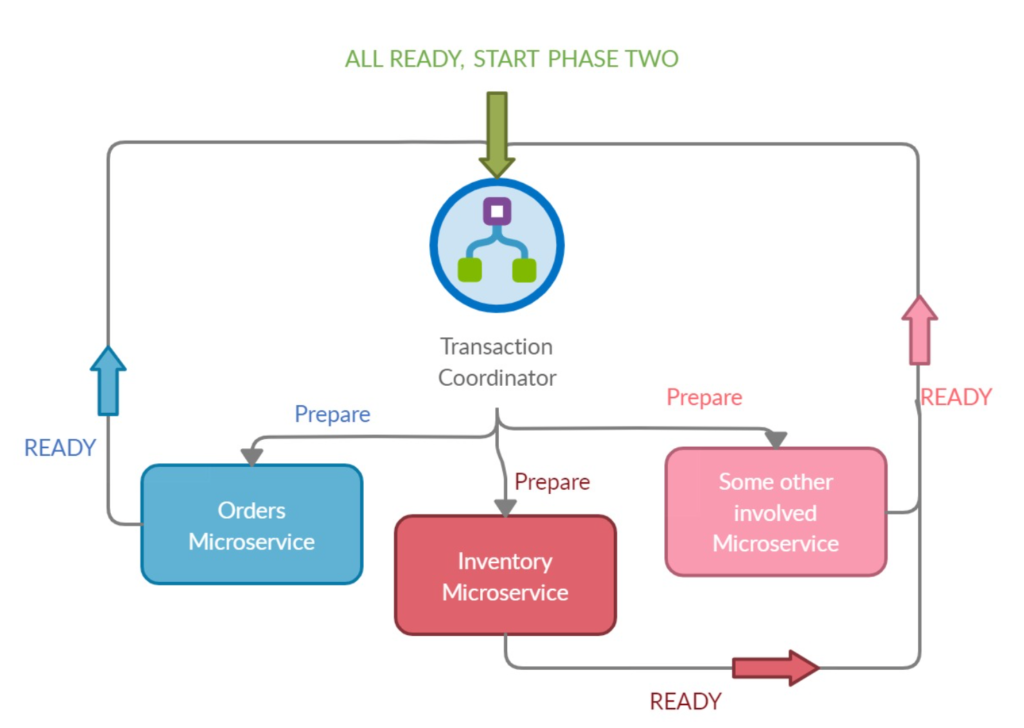
- Prepare Phase: The transaction coordinator asks all the microservices which are involved in a transaction to prepare for a data change. Once all the microservices respond “Ready”, the operation moves on to the second phase. If any of the microservices are unresponsive due to any reason (like request timed out, or a non ready response), the prepare phase fails and henceforth, the transaction fails with a Rollback. At this point, a graceful message to the user is sent, usually with a retry option.
- Commit Phase: Once all the services respond ready, the microservices are said to be prepared for the changes. At this point, the actual data changes are then applied in the commit phase.
Although the Two-Phase commit (2pc) ensures consistency and atomicity, it has its own disadvantages like:
- Object Locking: 2pc commit protocol is based on synchronous locking mechanism. In case there are multiple data changes involved across multiple microservices, it can lock the objects until the whole transaction either succeeds or fails. In above example, If a user buys 5 quantities of some item, then 5 quantities of that item will be blocked for other users as well. This is usually not optimal especially in case of eCommerce applications where only limited stock per item is available.
- High Latency and Delays: In case where the number of microservices involved in a transaction are many, and some microservice transactions take longer (for example one microservice involves payments handled by a third party), then the latency could be huge and they can cause a performance bottleneck for the entire application.
- Deadlocks: In some cases, two transactions can mutually lock each other. This can happen when two transactions are holding one object each, and both require the object which is held by the other transaction.
Saga Pattern
As we saw above, the 2pc is synchronous in nature and has its own set of drawbacks.
The Saga pattern handles the transactions by communicating with asynchronous events through all the microservices involved in a transaction. The data changes happen locally on each microservice and the success/failure of a change on each microservice is transmitted through asynchronous event bus.
In the example of an eCommerce transaction discussed above, the saga pattern would work in the following way:
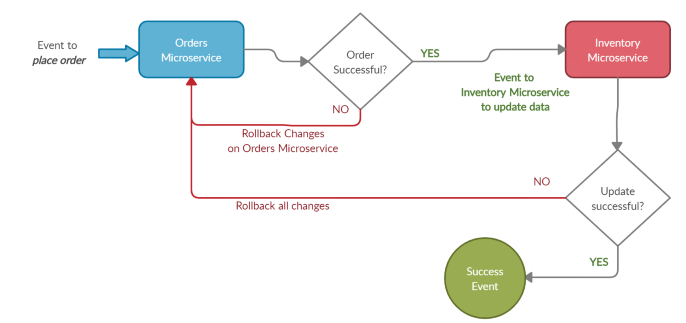
As we can see in the above diagram, If order is successful, an event is fired to the inventory microservice. On receiving the event, it starts the inventory update process. Once the inventory update succeeds, a success event is sent to other microservices involved. If no other microservices are involved, the transaction is complete. In this scenario, each microservice commits the transaction locally and communicates with other transactions through asynchronous events. In case any process in the microservice event chain fails, a failure event is sent back to ALL the microservices which were a part of the transaction before the failure, and the changes are rolled back.
In order to manage all these events efficiently, an orchestrator (or a process manager) is added to manage and coordinate all these events.
This process overcomes the shortcomings of the two-phase commit (2pc) pattern. There are no object locks because the transactions take place locally on each service. The performance impact is also reduced significantly because all the local transactions can also be configured to run in parallel.
From a performance perspective, this pattern is the go-to approach, but it is not without its disadvantages:
- Hard to debug: If the number of microservices involved in a transaction are too many, it becomes difficult to debug. This can, however, be minimized by adding a unique trace ID to all the requests at the point of origin. The trace ID for each request is passed on through all the microservices for a request. This could possibly give us the point of error if a request is failing at any node.
- Difficulties with read isolation: Since there are no locks on any object, the user could possibly see stale data in some situations. For example, a transaction completed locally on a particular microservice. After this local commit succeeds, another user tries to see this data. The user sees the updated data. So far so good? However, after the write on one microservice, some other microservice in the event chain may fail and send a failure event which leads to rollback of the write-transaction. In such a case, the reader has seen data which actually does not exist anymore (or is stale or old).
Each approach has its own shortcomings and advantages. There is no right or wrong in considering any approach. Having said that, each architecture & their requirements are different. Design patterns have to be tailored according to needs. While these patterns explore the possibilities of transactions in distributed microservices architecture, your needs may require you to develop a monolith architecture. It all depends on what you’re building 🙂